POOLS
Ceph 儲存叢集儲存資料在邏輯的分割區叫做Pools(池) ,你可以創建不同形式的池,像是區塊裝置(block devices)、物件閘道(object gateways),等等,並對不同的池簡單的將分開使用者和群組。
從客戶端的角度來看儲存叢集是很點單的,當一個Ceph客戶單想要讀寫數據(叫做一個i/o 存在的環境) ,其總是連接到Ceph 叢集的儲存池,客戶端會明確指出"池的名稱"、"使用者"、"密鑰",所以池會呈現相對應邏輯分割區對做資料物件做存取控制。
Ceph池不僅是用於存儲對像數據的邏輯分區,它扮演著至關重要的角色對 Ceph存儲集群如何分發和存儲數據 - 然而,這些複雜的操作對Ceph客戶端是完全透明的。
Pool 必須設定的參數
- 對象的所有權、訪問權
- PG數目
- 該Pool使用的CRUSH Ruleset
- 對象副本參數
Pool Type:
在早期的Ceph版本,一個Pool精簡的維護物件用多個深度複寫,今天,Ceph 可以維護物件用深度的複製和使用糾錯碼,由於確保data durability(數據持久)方法在深度複寫和糾錯碼之間的不同,Ceph 支持一個客戶端完全透明的池的類型。
CRUSH Ruleset:
高可用性,耐久性和性能在Ceph中非常重要。CRUSH演算法計算放儲存物件到一連串的OSD透過PG,CRUSH也扮演
另一個重要的角色即可以識別故障領域和性能領域(舉例:存儲介質和節點的類型、它們的位置在哪個機架,哪排等)。 CRUSH使客戶端能夠跨故障區域寫入數據(房間,機架,排等),所以如果群集中如果有一整櫃的機器故障,則集群仍然可以在降低效能狀態下運行,直到恢復。 CRUSH使客戶端能夠寫入數據到特定類型的硬件(性能領域),如SSD存放日誌或將數據存到具有與相裝置上的硬碟上。 CRUSH Ruleset 決定池的故障領域和性領能域。
Durability:
在超級大容量存儲集群中,硬件故障是一種會發生但不可預期的例外。當使用數據物件來表示較大粒度(larger-grained)的存儲接口,如區塊設備,丟失一個或多個數據物件較大粒度的接口可能會危害
較大粒度存儲實體的完整性 - 可能使其無用。所以數據丟失是
不能容忍的。 Ceph以兩種方式提供高數據耐久性:首先,在故障域副本池將存儲多個
使用CRUSH的深入複製物件,以物理分離一個數據對象
(即副本分發到分開的硬件)。這增加了硬件的耐用性。其次,糾錯編碼池將每個對象存儲為K + M塊,其中
K表示數據塊,M表示編碼塊。其總和表示
用於存儲對象OSD的數量,M值表示可以失敗的OSD數量,也就是說如果M個OSD失敗,數據仍然可以回復。
POOL調用的關係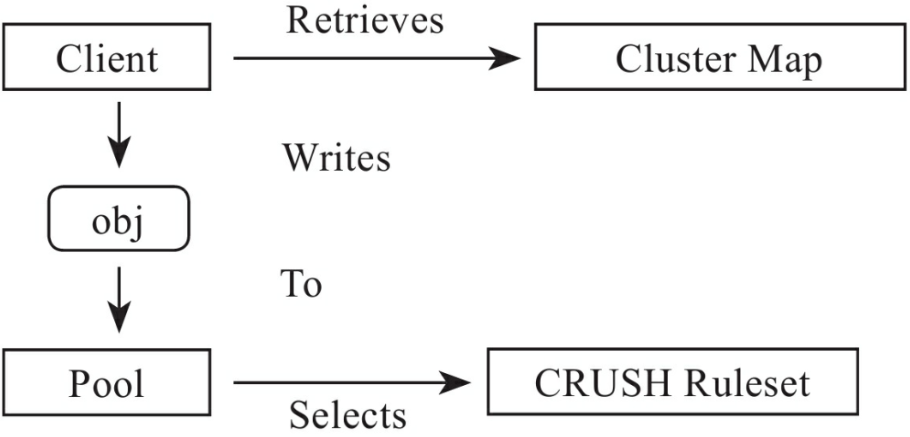
物件與PG和Pool的關係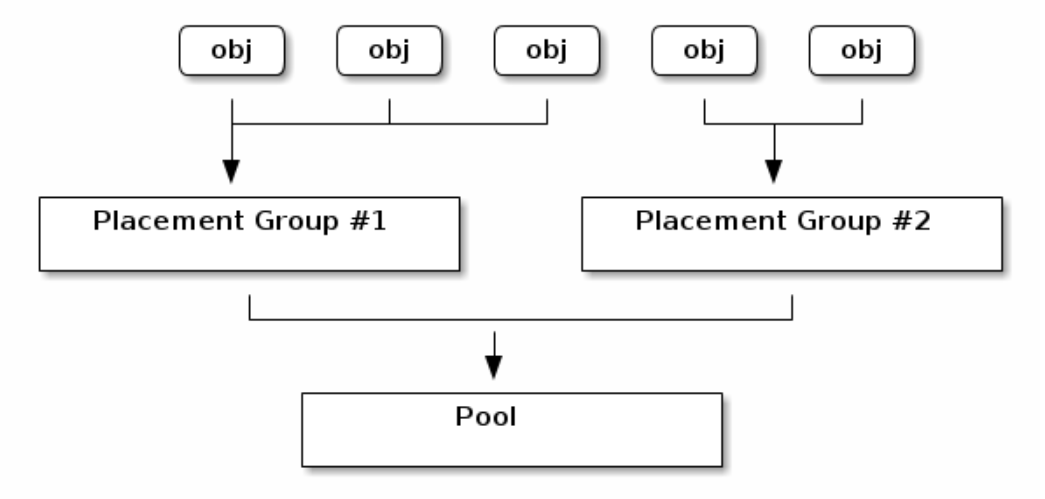 複寫池(replicated pool)中的PG複製到兩個OSD
複寫池(replicated pool)中的PG複製到兩個OSD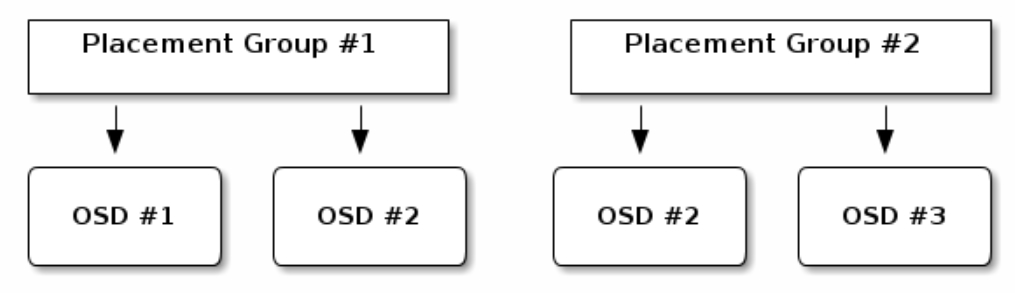 數據分配
數據分配
- 當檔案條帶化後含有很多物件<由物件的序號和檔案的元數據結合成OID>
- Ceph叢集把很多物件放入歸置群<將OID哈希後再做MASK後得到PGID>
- CRUSH 分派歸置群到N個OSD的集合,N為副本數,第一個OSD稱做主OSD,其它的OSD則為從OSD。
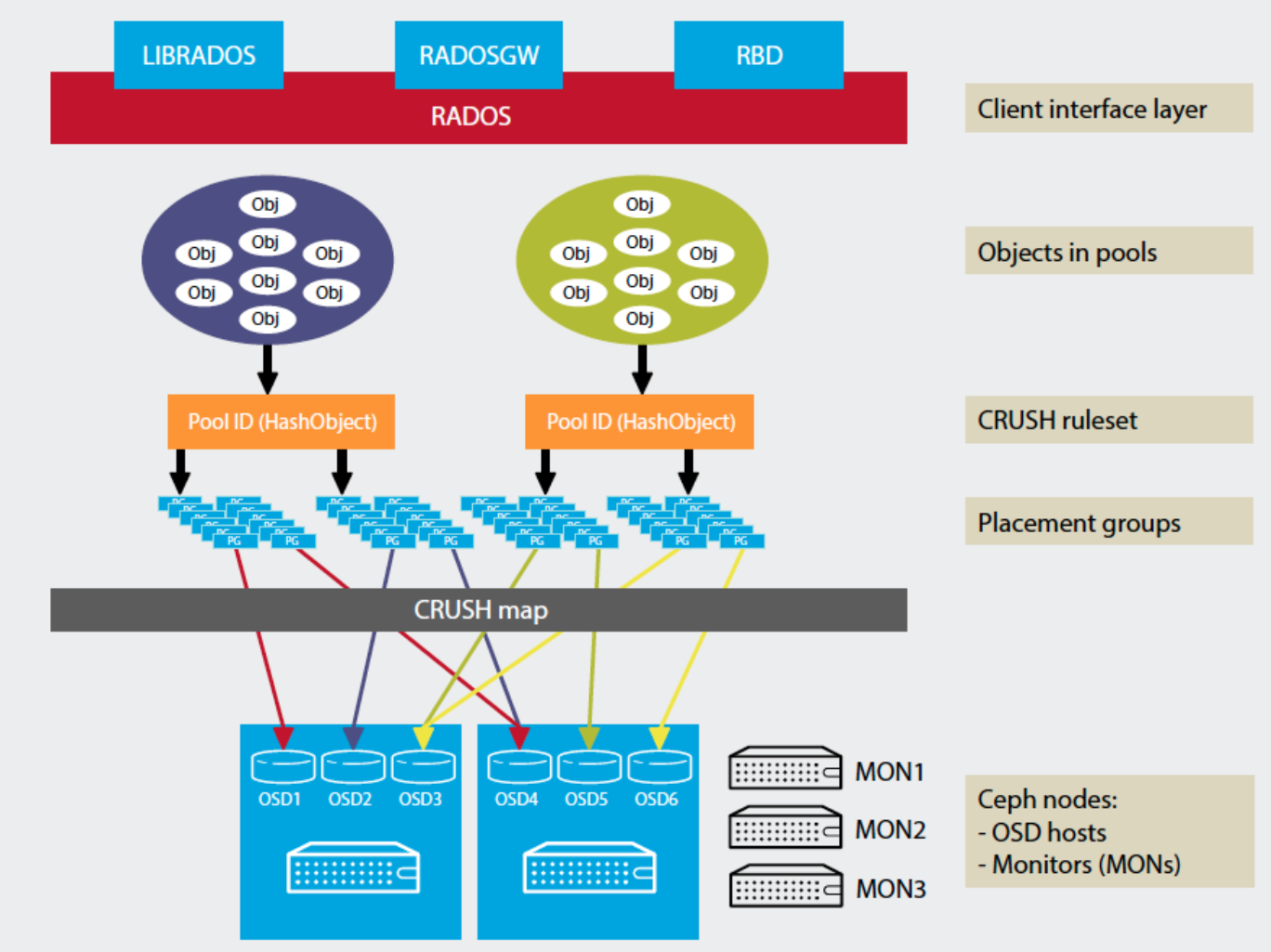
上圖補充
CRUSH演算法算出的OSD不一定是一成不變的,主要有兩個因素影響
- 當前系統的狀態
- 儲存策略的配置
一般儲存策略剛開始就會訂好,一般都是複製三份,但當前系統狀態有可能會因為硬體的故障或集群的擴展而改變,然而Ceph會把PG與OSD之間映射關係發生變化做再平衡(rebalancing)。
上圖中上半部是用一般的Hash下半部則是CRUSH,CRUSH在此展現其特殊性
- 可以配置OSD物理映射的策略
- 如果OSD故障或新增時,大部分的PG與OSD映射關係部會改變,只有少部分PG的映射會發生變化而引發數據遷移。